
Reto o necesidad que resuelve
La empresa tiene la necesidad de disponer de un aplicativo que le permita predecir la producción de mango y aguacate para la campaña venidera. El objeto es poder hacer una buena previsión de los recursos necesarios para la cosecha y post-cosecha (mano de obra, maquinaria, etc.).
Solución
Se ha desarrollado una solución basada en los siguientes elementos:
- Proceso de Extracción, Transformación y Carga de los Datos
Tal y como se puede observar en la Figura 1(A), se diseñó un proceso automatizado de ETL para poder extraer, transformar y cargar los datos proporcionados por la empresa. Estos datos consistían en un histórico procedente de un total de 57 fincas de mango y aguacate. La estructura de los datos fue suministrada en forma de Tablas Excel (Bases de datos relacional), donde figuraban variables de interés agronómico, así como otras relacionadas con la cantidad de árboles y variedades distintas dispuestas en cada una de las fincas. Además, también se hacía referencia a la situación geográfica de cada una de las parcelas, lo que resultaba imprescindible para poder establecer las condiciones climáticas específicas de cada una de las localizaciones. El proceso ETL consistió básicamente en automatizar un proceso que permitiera unificar, normalizar y realizar la transformación necesaria de los datos para poder llevar a cabo un análisis exploratorio, que permitiera identificar patrones de comportamiento de las variables predictoras sobre la variable objeto que se quiere predecir.
- Análisis y Enriquecimiento de los Datos
Una vez finalizada la automatización del proceso ETL, se procedió con el análisis exploratorio de los datos (Figura 1(B)). El objetivo principal consistió en identificar patrones en las variables predictoras que pudieran influir sobre el comportamiento de la variable objeto que se quería predecir, concretamente la producción de fruta. Se comprobó la influencia de la edad, el número de árboles, la dotación de riego, la variedad, la superficie de cultivo productora, etc. sobre la producción de los árboles. Así mismo, también se comprobó el efecto clima, así como la influencia de la localización geográfica sobre la productividad. Por último, antes de proceder con el entrenamiento y la implementación de los modelos predictivos, se llevó a cabo un enriquecimiento de los datos. En este sentido, se priorizó la idea de intentar reflejar una variable que representara la proporción de fruta cuajada (ratio de cuajado) y se intentó, en base al histórico disponible, detectar el efecto de la vecería (alternancia de la capacidad productiva entre campañas), fenómeno asociado a las dos especies en estudio. Tras llevar a cabo la aproximación a estas variables, se pudo ver claramente un efecto importante de estas variables sobre la respuesta productiva. Además, con estas variables también se pretendía tener independencia de las variables clima, pues tanto el ratio de cuajado, como la vecería podrían ser consideradas como variables cuya respuesta es el reflejo de las condiciones climáticas a las que han sido sometidas los árboles.
- Implementación y evaluación de los modelos de IA
Tras llevar a cabo el análisis exploratorio de los datos, se comenzaron a probar combinaciones de variables y diferentes modelos de Inteligencia Artificial (modelos de aprendizaje automático supervisados). Se probaron tanto modelos de Machine Learning (basados en árboles de decisión), como de Deep Learning (redes neuronales). Los mejores resultados se obtuvieron utilizando los modelos de Machine Learning basados en árboles de decisión, concretamente el XGBoost, tal y como se puede observar en la Figura 1(C). Los resultados obtenidos para aguacate se presentan en la Figura 2. Como se puede observar, tras realizar distintas combinaciones de variables y aplicar filtros para eliminar valores atípicos que podían causar efectos significativos sobre el modelo predictivo, se consiguió establecer una precisión del modelo, según medida de la Raíz del Error Medio Cuadrático, del 11.46% en datos de prueba y del 2.72% con el conjunto completo de datos.
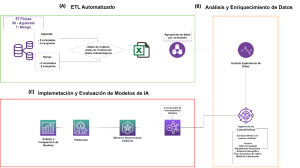
Figura 1. Solución desarrollada para implementar el modelo de predicción de la producción de aguacate y mango. (A). Extracción, carga y transformación de los datos suministrados por la empresa (ETL Automatizado); (B). Análisis exploratorio de los datos facilitados por la empresa (Análisis y Enriquecimiento de los Datos); (C). Diseño, implementación y evaluación de los modelos de Inteligencia Artificial (Implementación y Evaluación de los modelos de IA).
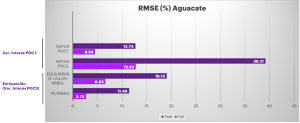
Figura 2. Evaluación del desempeño del modelo implementado.
- Despliegue de la solución (versión Demo)
Después de implementar y evaluar el modelo predictivo, se decidió llevar a cabo una versión demo del despliegue de ese modelo predictivo en una interfaz de usuario (API) basada en FAST API, que consistió en una interfaz visual donde estaban definidas las variables predictivas a partir de las cuales se proporcionaba un valor predicho de la estimación de la producción, según especie y cultivar o variedad productiva.
Este despliegue, como se ha indicado, es una versión demo. No obstante, se podría generar una versión funcional en producción a través de una solución acorde a las necesidades funcionales de la empresa (Microservicios Cloud, herramienta de Business Intelligence, etc.).
Empresas cliente
Trops
Tecnologías involucradas
Como se describe en el apartado anterior, la solución se ha desarrollo utilizando lenguaje Python y sus librerías asociadas, se han utilizado tecnologías basadas en IA, concretamente modelos de aprendizaje automático supervisado. Así mismo, para generar el aplicativo, se ha desarrollado una API (versión demo) que permite estimar la producción de mango y aguacate en función de unos parámetros, principalmente variables agronómicas de interés productivo disponibles por la empresa en sus bases de datos.